服务热线
服务热线
像人类一样能够自主感知环境、思考决策,做出行动

Awaker通过对多模态大模型的训练,使AI具备像人类一样对文字、图片和音视频的理解能力、推理能力、互动能力。技术上已经实现了图生文、文生图、视频生文、文生视频等多模态全方位的智能交互能力。
- 支持多模态多任务包括文本对话、图文对话、视觉生成、复杂推理、视觉检测、文本检测、OCR等
- 更懂中文集文本、图像、视频、音频等多模态信息联合训练,更加适应中文的语言环境


Awaker通用多模态大模型
是视觉理解与生成的超级融合

多媒体内容搜索视频素材搜索与管理

视频搜索剪辑生成按需搜索照片视频、素材一键成片、文生视频

智慧巡检光伏、电力、城管、水务、安防

机器人感知决策机器人人机交互,语音、识别、分析

市场营销按需生成市场营销物料

应用产品ToC的消费级应用产品

影视动画文本—图像,提供影视动画素材

数字孪生快捷生成城市数字孪生模型

具身智能通过感知和交互与环境进行实时互动

教育教学个性化智能辅助教育,促进学生更好地成长

医疗健康助推中医药建设,赋能中医药传承创新发展

文化传媒驱动数字文化产业高质量发展


- 对话大模型
- 图生文
- 图文会话

请详细描述这张照片

这张照片是一副名为“星夜”的画作,作者是荷兰画家梵高,画面中我们可以看到繁星点点的星空,星星仿佛在跳跃,而地面上则是个小镇和一些树木,画面中央还有一栋高塔。整幅画笔...

图形中会带来的结果

如果任由火势燃烧,可能会引发周边的可燃物着火,造成更大的火灾。同时,燃烧产生的烟尘和有害气体会对环境造成污染,对人的健康也会造成危害。因此,应该尽快扑灭火灾,避免造成更大的损失。

作一首诗

城市上空彩虹出,霓虹闪烁夜色繁, 人潮涌动忙碌里,自然鬼斧神工显, 点缀都市瑰丽画,令人心中生欢喜。

他现在情绪如何

他看起来有点沮丧或失落,因为他坐在沙发上,把手放在脸上,可能在思考或担心着什么事情。

她在做什么

这段视频中,女人坐在汽车里,看起来她在使用手机。

如果给这个图布置灯光,怎么设置合适?

从图片来看,客厅的主色调是白色,建议使用柔和的黄色光线来增加温馨感,适当的摆放一些落地灯来营造环境氛围。另外,窗帘也可以起到柔化灯光的作用,选择具有穿透性的窗帘能够增加室内的来光度。地毯可以选择颜色深浅适中的,搭配上深色的装饰品,让这个空间更加协调统一。

图中场景会不会有危险

无法判断该场景是否存在危险,因为没有描述具体情境或危险因素。但是,由于囚犯们争斗,所以这个场景可能是比较混乱和不安全的。

图中管道是否需要报警维修?

是的,图中管道有一段不完整,需要报警维修。

01/08信息解读

请详细描述这张照片
这张照片是一副名为“星夜”的画作,作者是荷兰画家梵高,画面中我们可以看到繁星点点的星空,星星仿佛在跳跃,而地面上则是个小镇和一些树木,画面中央还有一栋高塔。整幅画笔...
图形中会带来的结果
如果任由火势燃烧,可能会引发周边的可燃物着火,造成更大的火灾。同时,燃烧产生的烟尘和有害气体会对环境造成污染,对人的健康也会造成危害。因此,应该尽快扑灭火灾,避免造成更大的损失。
作一首诗
城市上空彩虹出,霓虹闪烁夜色繁, 人潮涌动忙碌里,自然鬼斧神工显, 点缀都市瑰丽画,令人心中生欢喜。
他现在情绪如何
他看起来有点沮丧或失落,因为他坐在沙发上,把手放在脸上,可能在思考或担心着什么事情。
她在做什么
这段视频中,女人坐在汽车里,看起来她在使用手机。
如果给这个图布置灯光,怎么设置合适?
从图片来看,客厅的主色调是白色,建议使用柔和的黄色光线来增加温馨感,适当的摆放一些落地灯来营造环境氛围。另外,窗帘也可以起到柔化灯光的作用,选择具有穿透性的窗帘能够增加室内的来光度。地毯可以选择颜色深浅适中的,搭配上深色的装饰品,让这个空间更加协调统一。
图中场景会不会有危险
无法判断该场景是否存在危险,因为没有描述具体情境或危险因素。但是,由于囚犯们争斗,所以这个场景可能是比较混乱和不安全的。
图中管道是否需要报警维修?
是的,图中管道有一段不完整,需要报警维修。
支持高效微调和量化模型

多模态理解能够同时处理视觉信息和文本信息,对真实世界有更深层次的了解

高效微调在预训练模型基础上进行高效的微调,通过少量样本快速适应特定的业务需求和对话场景

量化模型为了提高推理速度和降低显存占用,Awaker-VL还提供了量化版本,该版本在效果评测上几乎无损,并在显存占用和推理速度上具有明显优势
- 检索大模型
- 以图搜文
- 以文搜图
应用场景
 图文特征匹配与检索通过计算图像和文本之间的相似度,Awaker-Sou可以用于匹配图像和文本,实现图文跨模态检索功能,用户可以上传一张图片或输入一段描述,系统通过Awaker-Sou模型找到与之最匹配的文本或图像,适用于电商、社交媒体等平台
图文特征匹配与检索通过计算图像和文本之间的相似度,Awaker-Sou可以用于匹配图像和文本,实现图文跨模态检索功能,用户可以上传一张图片或输入一段描述,系统通过Awaker-Sou模型找到与之最匹配的文本或图像,适用于电商、社交媒体等平台
 零样本图像分类Awaker-Sou模型具备zero-shot迁移能力,可以用于没有训练样本的图像分类任务,这在需要快速适应新类别的场景中非常有价值
零样本图像分类Awaker-Sou模型具备zero-shot迁移能力,可以用于没有训练样本的图像分类任务,这在需要快速适应新类别的场景中非常有价值 内容推荐系统在内容推荐系统中, Awaker-Sou可以帮助理解用户上传图片的内容,进而推荐相关的文章、视频或其他媒体内容
内容推荐系统在内容推荐系统中, Awaker-Sou可以帮助理解用户上传图片的内容,进而推荐相关的文章、视频或其他媒体内容 视频检索多模态数据检索可以用于视频检索,使用户能够使用视频片段或关键帧来搜索相关的文本信息、其他相关视频片段或图像
视频检索多模态数据检索可以用于视频检索,使用户能够使用视频片段或关键帧来搜索相关的文本信息、其他相关视频片段或图像
类人化搜索引擎能力
看的懂
具备像人一样识别和理解画面内容的能力
听的懂
具备像人一样对语言指令的语义理解能力(包括人的情绪、人物空间环境的关系),能识别人类语境中表达的意图,而非简单的关键词对应
- 01接收人性化
语言表达 - 02理解指令
并检索 - 03批量识别
并返回 - 04利用人类选择
结果学习
指令举例:士兵踩到地雷,人和狼在搏斗,郁闷的小狗


- 生成大模型
- 文生视频
- 图生视频
类人化生成能力


超写实的人像视频生成使用我们自己收集的大量高质量人像写真视频作为训练数据,训练得到的模型能够生成高质量的超写实人像视频,而非卡通等风格


忠于参考图像利用参考网络提取参考图像的整体信息,利用图像编码器抽取参考图像的语义信息,使生成的视频可以保持参考图像的环境、背景,以及人像的穿着和装扮等信息
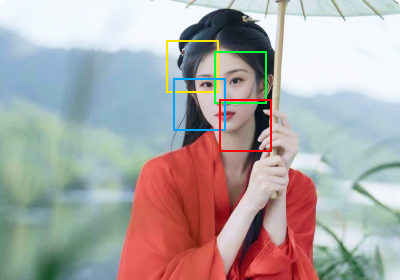

人像身份的保持除了对参考图像整体的保持,我们专门注入人脸信息,以及使用骨架动作作为条件,对于人像这个特定的题材做了建模,使生成的视频能够很好地保持人脸特征,也能够让肢体协调


 服务热线
服务热线


 服务热线
服务热线 产品服务
产品服务 支持合作
支持合作 微信公众号
微信公众号 在线客服
在线客服